
Sentiment Analysis on Twitter Data
Sentiment Analysis This is a summary of a homework for Statistical Learning Theory LAB at the FSU Jena. The paper used the word embedding Word2Vec under the assumption, that context information is relevant to predicting a sentiment. Also, a bibliographic approach VADER was investigated.
You can find a CSV-file with results here.
From a philosophical standpoint, it's an almost comic endeavour to teach a machine to accurately interpret human language and which feelings they intend to induce in their fellow human beings. It gets more absurd upon reflection, for which purposes sentiment analysis is being conducted: mostly product success metrics, which track specific groups of users, possibly over time, to reinforce the relationship between a brand and said users.
Data characteristics
Twitter data is difficult to interpret for two reasons: Words are context dependent. The context in tweets is about 45 words, so very limited. "Woke up on time today. Yay. Maths first, then French! not so 'Yay.'" Would we only be looking for words with negative or positive sentiment, we get 'Yay' twice, indicating positive. However, the sentence is classified as negative.
First Hypothesis
Therefore, I conclude that word positioning is important and choose Word2Vec. The figure shows a 2D-visualisation of the embedded messages. The colors blue and red indicate sentiment. It is very clear, that the embedding is hardly differentiating, as both sentiments are generally mixed. So, two methods were tried: Decision Trees (because we could see some mostly homogenous regions) and Logistic Regression.
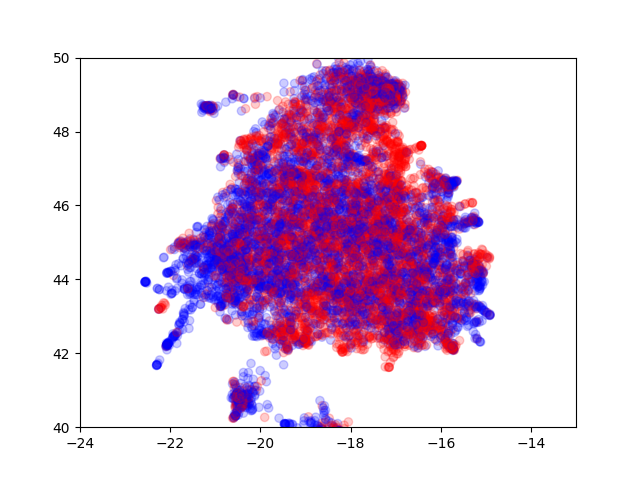
Well, best I could do was ~0.745.
Second Hypothesis
I proposed, that using bibliographic methods I could divide the sea -- and indeed!
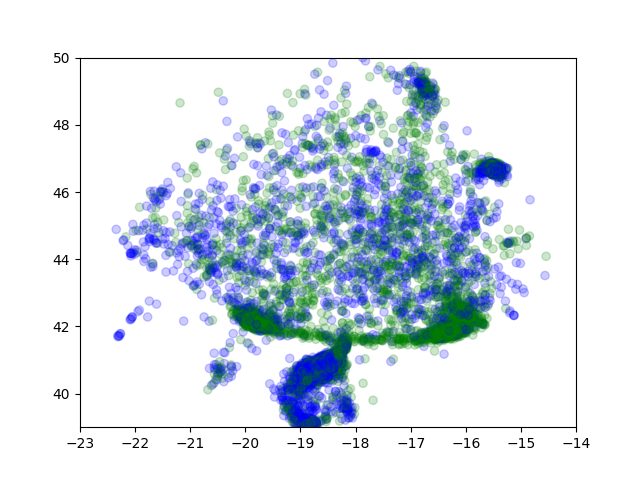
The graph shows a reef-like structure and a homogenous blob at the bottom. Sadly, the scores were only ~0.755.
Conclusion
I learned that pre-processing is important. My approaches (for this see the paper) were either insufficient or too radical. Fellow students
Future Work
I want to make explanations using LIME, to understand why my predictions were so bad. Fellow students achieved scores above 0.83 using Bag-of-Words. Therefore, I need to investigate whether positional information is advantageous, which I initially assumed.
Acknowledgements
Special thanks to Johannes; you helped me to understand what was going wrong and offered new perspectives. I also thank Paul for the great lecture! It helped to thoroughly understand the contents of the main module, Fundamentals of Algorithmic Learning Theory. The two lectures left me with a future-relevant toolbox.